Modele językowe kłamią. Nie ze złośliwości. Po prostu ich wiedza kończy się w dniu, kiedy zakończyło się szkolenie, a pytasz je o coś, co wydarzyło się tydzień temu. RAG system (Retrieval-Augmented Generation) to architektura, która naprawia ten problem: łączy AI z aktualną bazą dokumentów i generuje odpowiedzi zakorzenione w prawdziwych źródłach, a nie w tym, co model kiedyś „przeczytał” podczas treningu.
Zainteresowanie RAG eksplodowało po 2022 roku, kiedy firmy zaczęły wdrażać LLM-y do obsługi wewnętrznych danych. Problem był szybko widoczny: ChatGPT zna świat do jakiejś daty granicznej, nie zna twojego regulaminu wewnętrznego, twoich procedur ani treści umów z kontrahentami. Odpowiadał, owszem. Ale odpowiadał z siebie, nie z faktów. To był impuls do upowszechnienia RAG jako standardu produkcyjnego.
Skąd biorą się halucynacje i dlaczego sam LLM sobie z tym nie radzi
Duży model językowy to, technicznie rzecz biorąc, sieć neuronowa skompresowana do miliardów parametrów. Podczas treningu pochłonął gigantyczne ilości tekstu i nauczył się statystycznie przewidywać, jakie słowo powinno pojawić się po poprzednim. Efekt? Płynna, przekonująca mowa. Ale nie ma tam żadnej „bazy faktów” w klasycznym sensie: jest wzorzec językowy, z którego model interpoluje odpowiedzi.
I tu zaczyna się problem. Jeśli model nie spotkał danej informacji podczas treningu, albo spotkał ją tylko raz, albo wypada mu gdzieś w głębokich warstwach sieci; zaczyna interpolować. Czyli: wymyślać coś, co brzmi prawdopodobnie. Halucynacja to właśnie to: odpowiedź przekonująca językowo, fałszywa faktycznie.
GPT-3.5 miał okno kontekstu 8 000 tokenów; nawet przy rozszerzeniu do 32 000 tokenów nie zmieścisz w prompcie całej firmowej dokumentacji liczącej kilka tysięcy stron. Stąd pomysł: zamiast podawać modelowi wszystko, podaj mu tylko to, czego aktualnie potrzebuje do odpowiedzi na konkretne pytanie. Tak właśnie działa RAG.
Jak RAG działa od środka: retriever, embedding i generator
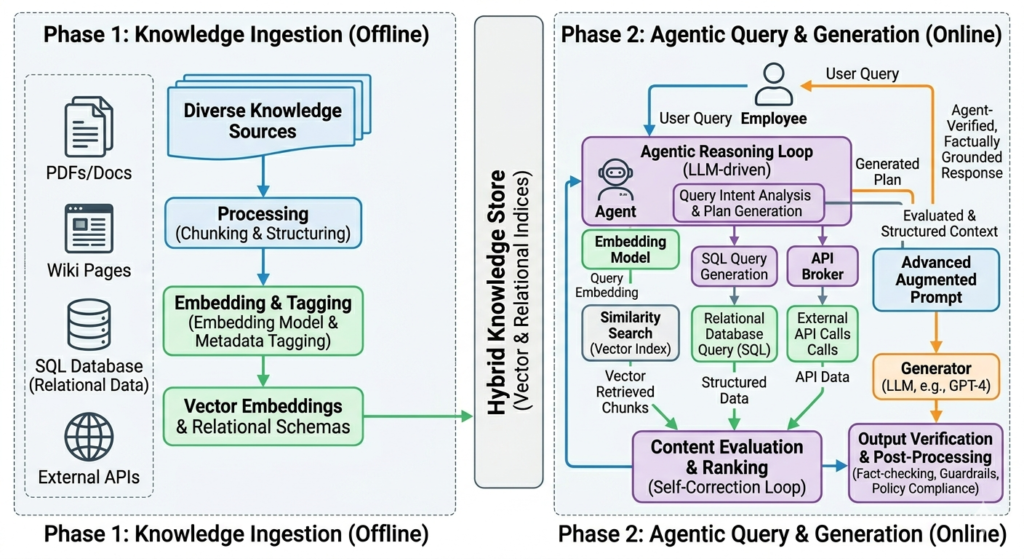
Architektura RAG składa się z dwóch głównych modułów: retrievera (komponent wyszukiwania) i generatora (model językowy). Retriever w czasie rzeczywistym przeszukuje zewnętrzną bazę dokumentów; generator na podstawie znalezionych fragmentów formułuje odpowiedź. To proste w opisie, ale diabeł tkwi w szczegółach każdego kroku.
Krok 1: indeksowanie dokumentów
Zanim system w ogóle odpowie na pierwsze pytanie, trzeba go nakarmić wiedzą. Dokumenty (pliki PDF, strony HTML, artykuły, bazy wiedzy) są cięte na mniejsze fragmenty, tzw. chunki. Każdy chunk jest zamieniany na wektor liczbowy (embedding) za pomocą osobnego modelu (np. text-embedding-3-large od OpenAI albo open-source’owych modeli jak BGE). Wektory trafiają do bazy wektorowej (Pinecone, Weaviate, Qdrant, pgvector). Tyle z przygotowania.
Krok 2: zapytanie i wyszukiwanie semantyczne
Kiedy użytkownik wpisuje pytanie, system zamienia je na ten sam typ wektora co dokumenty i szuka w bazie fragmentów semantycznie najbliższych, a nie metodą szukania dokładnych słów kluczowych, ale przez porównanie geometryczne wektorów. Odległość kosinusowa między wektorami mówi: „to zdanie dotyczy podobnego tematu”. System pobiera 3-10 najbardziej pasujących chunków.
Krok 3: generowanie odpowiedzi z kontekstem
Pobrane fragmenty trafiają do promptu razem z oryginalnym pytaniem użytkownika. Model językowy dostaje więc: pytanie + konkretne informacje z dokumentów. Generuje odpowiedź wyłącznie na ich podstawie (przynajmniej w teorii). W dobrze skonfigurowanym systemie RAG, gdy żaden fragment nie zawiera odpowiedzi, model powinien przyznać, że nie wie. To mechanizm, który klasyczny LLM bez RAG praktycznie nie ma.
Gdzie RAG rzeczywiście działa i gdzie zawodzi
Nie każdy problem z AI rozwiąże się przez dodanie RAG. Mam tu konkretne doświadczenie: system działa znakomicie, gdy dokumentacja jest dobrze ustrukturyzowana, aktualna i opisuje rzeczy, o które rzeczywiście pytają użytkownicy. Gorzej, gdy karmisz go latami niespójnych wewnętrznych maili.
| Scenariusz | Wynik z RAG | Uwagi |
|---|---|---|
| Firmowy helpdesk oparty o dokumentację IT | Doskonały | Dokumentacja jest zwarta, techniczna, dobrze podzielona na sekcje |
| Analiza treści umów prawnych | Bardzo dobry | Pytania mają konkretne odpowiedzi w tekście; RAG umie zacytować klauzulę |
| Chatbot oparty o historię mailową firmy | Słaby | Chaotyczna struktura, sprzeczne informacje, brak metadanych kontekstu |
| Wsparcie diagnostyki w produkcji przemysłowej | Dobry | Manuały są schematyczne; chunking po sekcjach działa przewidywalnie |
| Ogólna wiedza dziedzinowa (np. medycyna) | Zmienny | Zależy od jakości i aktualności źródeł wpisanych do bazy wektorowej |
Ale jest jeszcze jeden problem, o którym mało kto mówi przy zachwalaniu RAG: chunking to trudna sztuka. Zbyt duże fragmenty: model dostaje za dużo szumu. Zbyt małe: chunk nie zawiera wystarczającego kontekstu, żeby odpowiedź miała sens. Nie istnieje universalny rozmiar chunku; 512 tokenów sprawdza się przy dokumentach prawnych, ale nie przy technicznych instrukcjach obsługi maszyn z tabelami i rysunkami.
RAG kontra długi kontekst i fine-tuning: co wybrać i kiedy
W lutym 2024 roku Google ogłosił Gemini 1.5 Pro z oknem kontekstu 1 miliona tokenów. Branża zaczęła pytać: po co w ogóle RAG, skoro możemy wrzucić całą bazę wiedzy prosto do promptu? Odpowiedź jest mniej oczywista niż wyglądało na początku.
Przetworzenie 1 miliona tokenów na GPT-4 Turbo kosztuje ok. 15 dolarów za pojedyncze wywołanie (to liczba z końca 2025 roku). Dla aplikacji z tysiącami zapytań dziennie taki model cenowy jest po prostu nieużywalny. RAG pobiera zwykle 3-10 małych fragmentów; prompt ma kilka tysięcy tokenów zamiast miliona. Koszt jest nieporównywalnie niższy.
Fine-tuning to zupełnie inny mechanizm: zamiast podawać wiedzę w prompcie, wtrącasz ją do wag modelu przez dodatkowe szkolenie. Działa świetnie, gdy chcesz zmienić styl wypowiedzi modelu, nauczyć go specjalistycznego żargonu albo konkretnego formatu odpowiedzi. Nie działa, gdy twoja baza wiedzy zmienia się co tydzień: każda zmiana wymaga ponownego fine-tuningu. RAG aktualizujesz przez dorzucenie nowych dokumentów do indeksu; nie potrzebujesz do tego GPU ani tygodnia czasu.
Jednak jeśli twoja baza wiedzy liczy mniej niż 100 stron i rzadko się zmienia, długi kontekst z cachingiem może być po prostu prostszy w utrzymaniu. Mniej infrastruktury, mniej punktów awarii, mniej konfiguracji chunkingu. Nie każde wdrożenie musi być eleganckie technicznie; liczy się, co działa niezawodnie w twoim konkretnym przypadku.
Jak wdrożyć RAG w firmie bez przepalania budżetu
Zanim wybierzesz narzędzie, zrób jeden krok wstecz. Jakie pytania użytkownicy zadają najczęściej i gdzie szukają odpowiedzi teraz? Jeśli odpowiedź brzmi: „przeszukują 400-stronicowy PDF regulaminu”: masz gotowy case. Jeśli odpowiedź to: „nie wiemy”: cofnij się do badania użytkowników, bo RAG na nieznany problem to drogi eksperyment.
- Zdefiniuj bazę wiedzy: wybierz konkretny zestaw dokumentów, nie „wszystko co mamy”. Zacznij od jednego działu lub jednego tematu; to pozwoli ocenić jakość systemu zanim zainwestujesz w pełną infrastrukturę.
- Przetestuj chunking na próbce: wytnij ręcznie 50 fragmentów i sprawdź, czy 10 typowych pytań użytkowników faktycznie znajdzie właściwy chunk w top-3 wynikach. Jeśli nie, popraw strategię podziału, zanim zindeksujesz tysiące stron.
- Wybierz bazę wektorową pod swoje potrzeby: Pinecone sprawdza się dla szybkich wdrożeń produkcyjnych (chmura zarządzana), Qdrant i Weaviate to solidne opcje open-source jeśli masz infrastrukturę własną, pgvector to dobra opcja jeśli już używasz PostgreSQL i nie chcesz dodatkowych komponentów.
- Ustaw granice modelu: jawnie instruuj LLM, żeby odpowiadał tylko na podstawie podanego kontekstu i przyznawał brak danych zamiast interpolować. Tego nie zrobisz, model wróci do swojej „wiedzy” z treningu i zacznie halucynować mimo RAG.
- Mierz jakość retrieval osobno od jakości generacji: to dwa oddzielne miejsca awarii; pomieszanie ich sprawia, że nie wiesz, gdzie szukać błędu gdy coś nie działa.
Najczęściej zadawane pytania o RAG
Czy RAG całkowicie eliminuje halucynacje w AI?
Nie całkowicie. To uczciwa odpowiedź, której wiele artykułów unika. RAG znacząco ogranicza halucynacje, bo model odpowiada na podstawie konkretnych pobranych fragmentów zamiast interpolować z pamięci. Jednak gdy retriever zwróci niepasujące fragmenty (co zdarza się przy słabym chunkingu lub niejednoznacznych pytaniach), model dalej może generować błędne odpowiedzi, tyle że tym razem „zakorzenione” w złym kontekście.
Jaka jest różnica między RAG a fine-tuningiem modelu?
Fine-tuning zmienia wewnętrzne wagi modelu przez dodatkowe szkolenie: uczy model nowego stylu, żargonu lub formatu odpowiedzi. RAG nie zmienia modelu w ogóle: podaje mu aktualną wiedzę w prompcie w czasie rzeczywistym. Jeśli twoja baza wiedzy zmienia się często, RAG jest o wiele bardziej praktyczny; fine-tuning wymaga ponownego trenowania przy każdej istotnej zmianie danych.
Co to jest baza wektorowa i dlaczego RAG jej potrzebuje?
Baza wektorowa (np. Pinecone, Weaviate, Qdrant) przechowuje dokumenty zamienione na wielowymiarowe wektory liczbowe zwane embeddingami. Zamiast szukać dokumentów przez dopasowanie słów kluczowych, system porównuje wektory geometrycznie i znajduje fragmenty semantycznie podobne do zapytania. To pozwala znaleźć właściwy rozdział regulaminu nawet gdy użytkownik użył zupełnie innych słów niż te w dokumencie.
Ile kosztuje zbudowanie systemu RAG?
Widełki są bardzo szerokie. Prototyp oparty o LangChain, Qdrant (open-source) i GPT-4o-mini można uruchomić w ciągu jednego dnia pracy dewelopera za kilka dolarów miesięcznie przy małym ruchu. Produkcyjne wdrożenie dla dużej firmy, z własnymi modelami embeddingów, monitoringiem jakości retrieval i zabezpieczeniami danych, to przedsięwzięcie na tygodnie i budżet rzędu kilkudziesięciu tysięcy złotych, w zależności od skali.
Jakie formaty dokumentów obsługuje RAG?
Technicznie niemal wszystkie: PDF, DOCX, HTML, Markdown, TXT, a przy odpowiednich loaderach (np. z biblioteki LlamaIndex) również arkusze kalkulacyjne, prezentacje i bazy danych. Trudniejsze przypadki to dokumenty silnie graficzne (schematy, tabele osadzone jako obrazy) oraz pliki ze złożonym układem kolumn; tu sam text-extraction często gubi kontekst i trzeba sięgnąć po modele multimodalne lub OCR z rozumieniem struktury.
Czy RAG można uruchomić lokalnie, bez wysyłania danych do chmury?
Tak. Lokalne LLM-y (Llama 3, Mistral, Qwen) w połączeniu z Ollama i lokalną bazą wektorową (np. Qdrant self-hosted lub Chroma) dają kompletny stos RAG bez jednego bajtu wysłanego poza firmową sieć. To szczególnie ważne dla firm przetwarzających wrażliwe dane medyczne, prawne lub finansowe. Jakość lokalnych modeli jest niższa niż GPT-4o, ale dla wyspecjalizowanych zastosowań z dobrze przygotowaną bazą wiedzy różnica bywa zaskakująco mała.
Kiedy RAG nie ma sensu i lepiej wybrać inną architekturę?
Gdy baza wiedzy liczy kilkadziesiąt stron i zmienia się rzadko: długi kontekst z cachingiem bywa prostszy i tańszy w utrzymaniu. Gdy potrzebujesz modelu z innym stylem pisania lub specjalistycznym słownictwem: to zadanie dla fine-tuningu, nie RAG. Gdy pytania wymagają rozumowania wieloetapowego (np. „porównaj warunki umowy z 2022 z warunkami z 2024 i wskaż rozbieżności”) ; sama architektura RAG może być niewystarczająca; tam lepiej sprawdzają się agentic workflows z wieloma wywołaniami i narzędziami.
Trzy rzeczy, które warto przemyśleć przed wdrożeniem RAG
RAG rozwiązuje prawdziwy problem. Ale nie jest plastrem na każdą ranę. Zanim zamawiasz infrastrukturę i rezerwujesz czas dewelopera, sprawdź trzy rzeczy.
Pierwsza: czy twoje dokumenty są w stanie, w którym człowiek potrafiłby w nich sprawnie szukać? Jeśli pracownik potrzebuje godziny, żeby znaleźć odpowiedź w istniejącej bazie wiedzy: RAG tego nie przyspieszy; najpierw trzeba uporządkować źródła. Śmieci na wejściu dają śmieci na wyjściu, bez wyjątku i bez względu na jakość użytego modelu.
Druga: kto będzie to utrzymywać? Każdy RAG wymaga pipleinu indeksowania nowych dokumentów, monitoringu jakości retrieval i reagowania na przypadki, kiedy model odpowiada źle. To nie jest system, który uruchamiasz raz i zapominasz; potrzebuje ciągłej opieki.
Trzecia, i może najważniejsza: zdefiniuj metrykę sukcesu zanim zaczniesz. „Zmniejszenie liczby pytań do helpdesku o 30% w ciągu 3 miesięcy” to dobra metryka. „Zobaczmy jak będzie działać”: to nie jest metryka, to rebus. Systemy RAG dają się mierzyć: retrieval precision (ile pobranych chunków było trafnych), answer faithfulness (czy odpowiedź wynika z kontekstu) i answer relevance (czy odpowiedź dotyczy tego, o co pytano). Bez pomiaru nie wiesz, czy cokolwiek ulepszyłeś.
Źródła i dalsze informacje
- Lewis, P. et al. „Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.” Proceedings of NeurIPS 2020. arxiv.org/abs/2005.11401
- Reliable Data Engineering. „RAG is DEAD!” Medium, styczeń 2026. link
- Su, W. et al. „Dynamic and Parametric Retrieval-Augmented Generation.” SIGIR 2025, Padwa, Włochy. arxiv.org
- Web Systems. „RAG w praktyce: nowy standard LLM i firmowych chatbotów AI”, grudzień 2025. web-systems.pl






